2023년 ICLR에 게재된 논문으로 Prescient Design, Genentech와 Naver AI Lab 소속이신 박남욱 님이 1저자로 저술한 논문이다. CL과 MIM의 속성을 실험을 통해 비교한 논문이고 대부분이 실험-분석의 반복으로 이루어져 있다.
Abstract
Self supervised learning(SSL)의 방법론 중 두 가지 Contrastive learning(CL)과 Masked image modeling(MIM)을 비교하는 실험을 여럿 진행하여 속성을 분석했으며 초록에서는 CL을 베이스로 짧게 요약해서 포인트를 짚어준다.
- CL이 MIM보다 global한 패턴 파악에 좋다
- CL은 저주파 신호는 MIM은 고주파 신호를 주로 학습한다.
- CL은 출력 부분의 layer가 MIM은 입력 부분의 layer가 학습에 중요한 역할을 한다.
이 세 문장만 읽어도 논문에 적힌 대부분의 내용을 읽었다고 봐도 될 정도이며 이후 내용은 이 세 가지 속성을 증명하기 위한 실험과 토론으로 구성되어 있다.
Introduction
CL은 SSL의 대표적 방법론이었으나 이후 등장한 MIM이 downstream task들에서 CL보다 좋은 성능을 보여주며 새로운 강자로 떠오르고 있다. 현재 MIM이 CL보다 대체적으로 좋은 건 자명하나 MIM이 언제나 CL보다 월등한 것은 아니다.
그렇다면 ViT를 통한 SSL을 할 때 둘 중 정확히 어떤 걸 써봐야 좋을까? 이 논문은 다양한 실험을 통해 CL과 MIM의 속성을 분석해 이 의문에 답해준다. 총 3가지 부분에서 ViT의 행동을 분석하는 실험을 진행한다.
- The behavior of self-attentions
- The transformation of the representations
- Position of lead role components
실험이 실험-분석의 흐름으로 진행된다고 했는데 이 세 가지는 그에 앞선 가정이라고 보면 될 것 같다. 예를 들어 self-attention이 CL과 MIM에서는 어떤 식으로 동작할지 화두를 던지고 그것을 여러 실험을 통해 분석하는 순서로 진행된다.
HOW DO SELF-ATTENTIONS BEHAVE?
위에서 언급했듣 MIM이 대다수의 경우에서 CL보다 우수하다고 알려졌지만 몇몇 task에서는 그렇지 않다.

위 그림에서 파란색이 MIM방법론 모델, 빨간색이 CL 방법론 모델들이다. 왼쪽 그림은 Fine tuning에서는 MIM이 Linear probing에서는 CL이 성능이 높음을 알 수 있다. 두번째 그림은 작은 size의 모델에서는 CL의 성능이 MIM을 앞서고 세 번째 그림은 CL이 MIM보다 detection task에서 성능이 뒤떨어짐을 보여준다.
CL mainly captures global relationships.

CL과 MIM의 Attention distance를 비교했을 때 출력증쪽에서 CL의 Attention distance가 MIM보다 높으므로 CL은 global한 관계를 MIM은 local한 관계를 포착하는데 유리하다고 볼 수 있다. (Attention distance란 ViT에서 q와 k의 distance를 의미하며 개념적으로는 CNN의 수용장과 비슷하다 )
Self-attentions of CL collapse into homogeneity

CL과 MIM의 query token들의 NMI를 비교한 것인데 후반부에서 CL이 MIM보다 NMI가 낮을 것을 확인할 수 있다. 즉 token들이 서로 의존한다기보다는 거의 동등한 역할을 한다는 것이다.
CL의 query token간의 상호정보량이 낮은 것은 self attention이 collapse했기 때문이라 가정하고 이를 증명하기 위해 추가적인 실험을 진행하였다.

왼쪽부터 순서대로 head간, 전후 layer간 그리고 토큰 간의 cosine similarity를 비교했는데 후반부에서 CL이 MIM보다 전반적으로 유사성이 높은 것을 알 수 있다. 저자는 이 부분에서 CL의 크기를 늘려도 성능이 증가하지 않을 가능성이 높다는 의견을 제시했다.
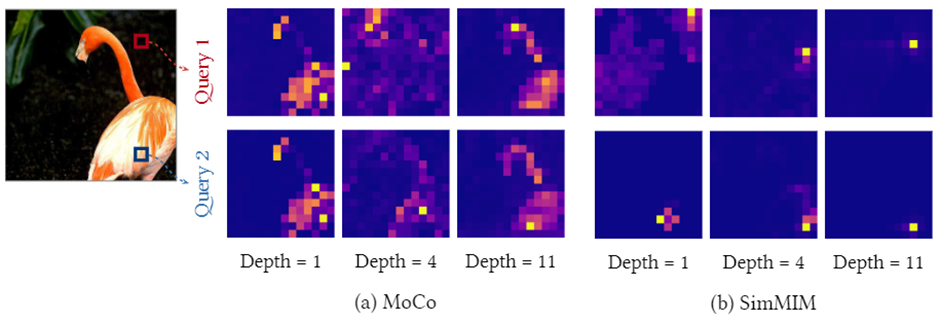
CL과 MIM의 token들의 attention map을 비교했을 때 CL은 layer가 깊어졌을 때 token들이 거의 유사한 부분에 집중하고 있는걸 볼 수 있다.
HOW ARE REPRESENTATIONS TRANSFORMED?
위의 실험으로 CL과 MIM의 token 분포가 다른 점을 알 수 있었는데 어째서 이런 현상이 일어났는지 여러 실험을 통해 분석한다.
CL transforms all tokens in unison, while MIM does so individually
CL과 MIM의 attention 이후 token들의 분포를 SVD를 통해 시각화하는 실험을 통해 이를 증명하려 했다.

CL은 모든 token들을 조금씩 움직이는 형태이고 MIM은 token 간의 거리를 벌어지게 하며 학습이 진행되게 한다. 이는 CL이 token을 거의 균등하게 처리한다는 것을 의미한다.
CL is shape-biased, but MIM is texture-biased.
왼쪽은 Stylize ImageNet을 사용한 즉 shape 정보에 노이즈를 준 것이고 오른쪽은 random한 noise를 준 즉 pixel에 노이즈를 준 것인데 각각 CL과 MIM의 성능 감소를 야기하는 걸 알 수 있다.

즉 CL은 토큰들은 균등하게 MIM은 개별적으로 처리하는데 이러한 부분이 CL은 shape정보를 main으로 MIM은 pixel정보를 메인으로 사용하여 SSL을 진행하게 된다는 뜻이다.
WHICH COMPONENTS PLAY AN IMPORTANT ROLE?
Later layers of CL and early layers of MIM are important.

위 그림은 각 layer의 representation을 linear-probing한 결과이다. 이를 통해 3가지 속성을 관찰했다고 한다.
- MIM은 초반에 CL은 후반부에 성능상승이 가파름
- CL은 성능이 계속 증가하나 MIM은 그러지 않음
- Linear probing에서는 MIM의 최고 성능도 CL을 이기지 못함
The explicit decoder helps ViTs further leverage the advantages of MIM

MAE와 MoCo는 둘 다 MIM기법이지만 유난히 MAE만 후반부의 NMI가 낮은 것을 알 수 있는데 이는 MAE가 다른 기법과는 달리 깊은 디코더를 사용했기 때문이라고 한다.
ARE THE TWO METHODS COMPLEMENTARY TO EACH OTHER?
여기까지 두 기법의 차이를 분석했으면 둘을 앙상블 해보지 않고 넘어갈 수는 없다.

왼쪽 그림은 두 모델의 비를 조절해 가면서 성능을 비교하는 한 실험 결과이다. 0~1까지의 값을 사용하며 0이 되면 MIM 1이 되면 CL이다. 두개의 비를 적절히 사용했을 때 Fine tuning과 Linear probing에서 기존보다 좋은 성능을 보여준다.
CONCLUSION
초록에서 말했던 세 가지 방법을 통해 CL과 MIM의 속성을 비교했으며 각 기법을 혼합하여 사용했을 때 더 좋은 성능을 얻을 수 있음을 실험으로 증명했다.
논문에서 가장 중요한 세 가지 속성을 다시 한번 강조하는데 원문에서 아래와 같이 표기했다.
- image information (image-level vs. token-level)
- feature representations (low-frequency vs. high-frequency)
- lead role components (later layers vs. early layers)
실험을 설명할때 attention distance와 같은 개념들을 잘 모르는 사람을 위해 간단히 설명해두었기 때문에 읽는데 막히는 부분은 딱히 없었다.
개인적으로는 CL의 attention map을 시각화할때 CL과 ViT를 결할할때의 단점이 크게 느껴졌다. transformer가 MHA를 쓰는 이유는 여러 head가 각각 다른 부분에 집중해주기를 바라서일텐데 CL은 이러한 장점을 살리지 못했다고 느꼈다.



