Contrastive learning Language-Image Pre-training(CLIP)은 openAI가 발표한 Constrative Learning을 사용해 Multimodal data의 representation을 학습하는 모델이다.
Abstract
기존의 CV모델들은 제한된 라벨 출력을 가지는 문제(restricted label problem)을 가지고 있었다. 이는 모델의 사용성을 저하시키는데 간단한 예시로 기존에 알지 못한 새로운 class가 출현했을때 대처하지 못하는 경우가 있다.
저자는 이를 image에 대한 caption을 예측하는 pretrain방식을 사용해 해결하려했다. 이 방식을 통해 훈련된 CLIP은 여러 task에 zero-shot transfer가 가능하며 기존의 Fully supervised 방식으로 학습된 SOTA모델과 경쟁이 가능하다.
Introduction and Motivation Work
NLP에서는 이미 task-agnostic 모델(BERT, GPT등)들의 성능이 입증되고 활발히 연구되고 있다. CV에서도 이런 시도를 한 연구도 많지만 NLP와 다르게 좋은 성과를 내진 못했다. 저자는 이 문제의 원인이 softmax classifier를 통한 예측의 정보표현에 한계가 있기 때문이라 주장했다.
Approach
Natural Language Supervision
생소한 단어인데 이는 기존의 연구들에서 혼용되게 사용한 단어(unsupervised, self-supervised, weakly supervised, and supervised respectively)의 의미를 포함하는 단어이며 자연어 감독을 추가하여 Image를 예측한다는 의미이다.
NLP 감독의 장점은 전통적 annotation이 필요없으며 정보의 표현이 아닌 관계를 학습하므로 zero-shot transfer가 가능하다는 점이다.
Creating a Sufficiently Large Dataset
NLP감독 모델들은 대용량 데이터 시나리오에 알맞은데 당시 저자가 원하는 정도의 대용량 데이터가 없거나 quality가 부족하여 4억 개의 (Image, text) pair dataset인 WebImage Text(WIT)를 인터넷에서 수집하여 만들었다.
Selecting an Efficient Pre-Training Method
기존의 연구는 각 데이터에 대한 representation을 만들기 위해 CNN과 Transformer를 학습시키는 방식을 사용했으나 이는 꽤 비효율적이었다. 따라서 Contrastive Learning을 사용해 정확한 예측을 하는 task에서 전체문장과 어울리는지 예측하는 task로 변경하였다. $N$size의 배치를 학습할때 $N^2$개의 text에 대해 예측하며 $N$개의 positive, $N^2-1$개의 negative sample로 구성된다.
Contrastive Learning은 양성 샘플 간의 거리를 가까이 음성 샘플 간의 거리를 멀리 학습하는 방법이다.
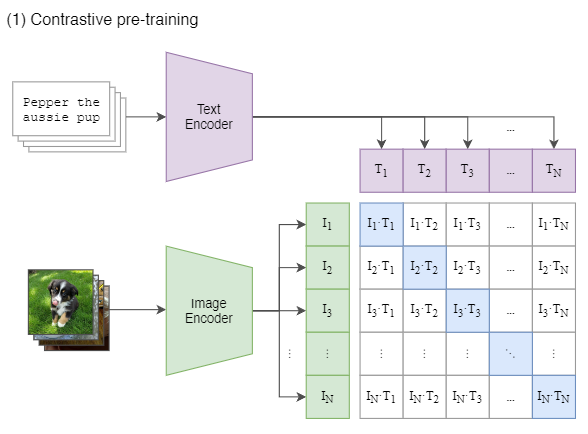
논문에 적힌 pseudocode를 통해 CLIP의 CL 시나리오를 대강 파악할 수 있다.

Choosing and Scailing a Model
CV encoder로 ResNet-D를 여러 깊이를 사용했으며 GAP를 Attention pooling으로 대체하였다. 추가로 ViT는 embedding에 Layer normalization만 추가하여 사용하였다.
NLP encoder로는 Transfomer를 사용했다.
Training
위의 아키텍쳐들의 여러 스케일의 모델을 사용하였는데 정확히는 ResNet-50, ResNet-101, Efficiently model style로 scaling한 RN50x4, RN50x16, RN50x64 그리고 ViT로는 ViT-B/32, ViT-B/16, ViT-L/14를 사용하였다.
내용이 길어 실험이후는 part2에서 이어 리뷰하겠습니다.
'Paper review' 카테고리의 다른 글
| What Do Self-Supervised Vision Transformers Learn?(2023) 리뷰 (1) | 2024.01.23 |
|---|---|
| Learning Transferable Visual Models From Natural Language Supervision(CLIP, 2021)리뷰 part-2 (0) | 2024.01.18 |
| Learning to Compare Relation Network for Few-Shot Learning(RelationNet, 2018) 리뷰 (1) | 2024.01.06 |
| GAN구현(Pytorch) (1) | 2023.12.22 |
| Generative Adversarial Nets(GAN, 2014) 리뷰 (1) | 2023.12.20 |



