이번에 리뷰할 논문은 적은 모바일 기기 사용을 위하여 개발된 MobileNet이다.
실제로 이 사이트에서 MobileNet과 다른 모델의 성능을 확인하여 볼 수 있다.

항목이 길기 때문에 일부만 가져왔는데 MobileNet이 다른 모델에 비하여 성능은 조금 낮지만 파라미터 수가 적고 예측시간이 빨라 모바일 기기에 적합하다는 것을 알 수 있다.
MobileNet 논문 리뷰
MobileNet은 depth-wise separable convolution 구조(Inception모듈 구조)를 사용하여 제작한 가벼운 가벼운 신경망 구조이다.
두가지 Hyperparameter를 조절하여 latency(예측 속도)와 accuracy의 trade off 관계를 고려해 모델을 선택할 수 있다.
Prior work and difference
딥러닝 모델의 경량화는 이전에도 자주 연구돼 왔던 분야이며 크게 두 가지 형태를 띤다.
- 큰 사이즈의 사전 훈련된 네트워크를 압축하는 경우
- 작은 사이즈의 네트워크를 처음부터 훈련시키는 경우
MobileNet은 이 중 작은 사이즈의 모델을 처음부터 훈련시키는 두 번째 카테고리에 속한다.
저자가 말하는 이전의 모델과의 차이점은 자원의 제한(latency, accuracy)에 맞추어 얼마나 작은 모델을 훈련시킬지 결정할 수 있다는 점이다.
Depthwise Separable Convolution
모델의 구조는 Inception 모듈에서 사용하는 Depthwise Separable Convolution을 사용하였다.
직역하면 깊이만 분리 가능한 컨볼루션인데 오히려 더 어지러운 느낌이니 그림으로 확인해보자.


왼쪽이 기존의 Convolution구조인데 이를 각 채널에 대하여 한번 Convolution을 거친다.
이후 한 점에 대하여 Convolution을 거쳐 공간과 채널을 별도로(Separable)하게 학습시키는 기법이다.
논문의 그림으로도 아직 어지러운 감이 조금 있기에 추가적으로 설명하면 아래와 같다.


Depthwise separable convolution을 통하여 연산량을 크게 감소시킬 수 있다.
대부분의 시각 네트워크가 3x3필터를 사용하므로 연산량을 9배에 가깝게 줄일 수 있다.
추가적으로 Convolution연산은 im2col로 변환된 다음 가중치와 행렬 곱을 통하여 구현되는데 1x1convolution1x1 convolution은 이와 같은 변환을 거칠 필요가 없으므로 메모리 낭비가 없어 효율적이다.
Hyper parameters

MobileNet은 Depthwise 연산을 통하여 충분히 작고 적은 지연시간을 가지게 되었지만 특정 task의 경우 더 빠르고 작은
모델이 필요할 수 있다. 이때 Width Multiplier a와 Resolution Multiplier p로 모델 사이즈를 더욱 줄일 수 있다.
a는 입력 채널에 각각 곱해져서 전체적인 채널 수를 줄여 parameter 및 연산량을 감소시키며,
p는 입력 이미지에 곱하여 전체적인 모델의 연산량을 줄인다. 입력 이미지 사이즈의 감소는 모델 연산량 감소뿐만 아니라 이미지 수집, 저장, 처리면에서도 큰 이득이다.
Architecture and Performance

연산 순서는 왼쪽 그림의 순서도에서 Depthwise Separable Convolution을 적용해 오른쪽으로 바뀌었으며
네트워크 구조는 오른쪽 그림과 같다.

ImageNet에 대한 Accuracy, 연산량, Parameter 수를 위의 표에서 확인할 수 있다.
표 5의 Shallow MobleNet은 중간의 풀링 없이 연산 되는 5개의 층을 제외하여 경량화시킨 모델이다.
비슷한 연산량과 파라미터를 가진 a를 조절한 MobileNet 모델보다 성능이 낮음을 확인할 수 있다.
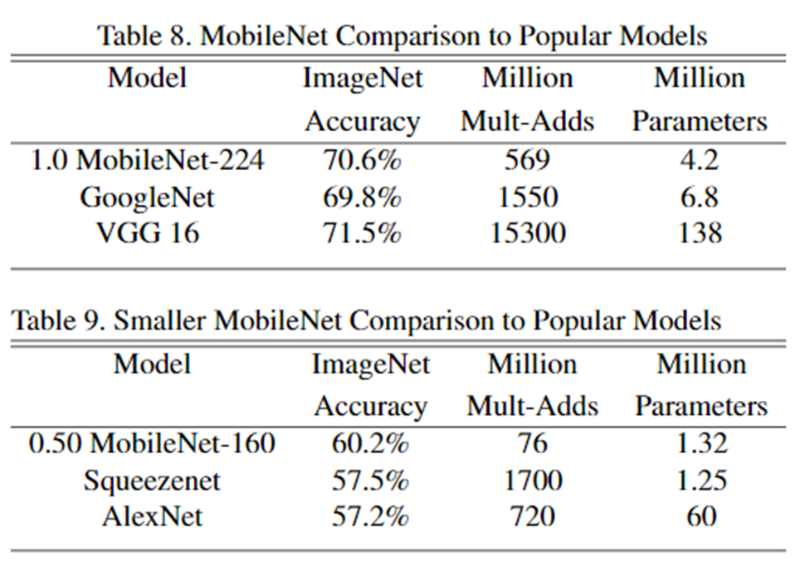
표 8을 통하여 이전의 최고 성능 모델에서 연산량과 파라미터수를 감소시켰음에도 큰 성능 차이가 없음을 확인할 수 있다.
표 9는 기존의 경량화 모델인 Squeezenet과의 비교이다.
연산량이 매우 적음에도 성능은 Squeezenet보다 높음을 확인할 수 있다.
논문에는 추가적으로 Object Detection, Fine Grained Recognition, Large Scale Geolocalization등과 같은 task에서 다른 모델과의 성능 역시 비교하며 여러 task에 적용 가능하다는점 역시 어필하였다.
Insights

이전까지 Inception모듈은 1x1Convoluiton1x1 Convoluiton과 각 채널에 대한 Convolution을 별도로 학습하여 채널과 공간정보 각각에 대한 별도 학습으로 인하여 성능을 증가시키는 기법으로 생각하였다.
하지만 MobileNet은 Inception의 parameter감소에 집중하였다.
기존에는 파라미터의 감소로 인하여 병렬적인 Convolution을 통한 성능 증가를 타겟으로 하였다.
MobileNet에서는 채널에 대하여 한번만 학습하여도 성능 저하가 없으면서 parameter는 크게 줄었다는 점에 주목하였다.
또한 전체적으로 당시 딥러닝의 트렌드에 대하여 다시 한번 생각하였다
연산의 분리 즉 ResNet의 skip-connection을 통한 정보 변형과 출력을 분리하였고
LSTM은 정보의 장기와 단기를, DenseNet 역시 정보 변형과 출력을 극단적으로 모든 층에서 분리하였다.
Transformer 등장 이전까지 굵직한 논문들은 대부분 이러한 연산의 분리를 통한 [파라미터 감소, 학습 부분 파편화, 학습 병렬화] 이 세 가지 중 하나를 메인 타겟으로 잡고 잘 쪼갠 논문들이 트렌드였던것 같다.
MobileNet 논문링크: https://arxiv.org/abs/1704.04861
참고 사진링크1: https://deepseow.tistory.com/12



