저번 한 달간 암석 분류 프로젝트를 진행하면서 이를 위하여 CNN모델을 생성하였습니다.
초반에 VGG base로 모델을 만들었는데 심하게 과대 적합하여 당시 알고 있던 방법을 총동원해도 val-accuracy 90%를
넘기는 게 쉽지 않았습니다. 이때 모델을 ResNet base로 바꾼 다음 Data augmentation을 사용하여 거의 100프로에 가까운 val-accuracy를 가지는 모델을 만들었습니다.
성공적으로 플젝을 제출하고 구조상 큰 차이가 없음에도 어떻게 큰 성능 발전을 보여준지 궁금하여 ResNet을 읽어 보았고 정리한 내용을 리뷰해보겠습니다.
ResNet 논문 리뷰

Abstract 부분에서 ResNet구조가 어떠한 의미로 고안되었는지 말해줍니다. 깊은 네트워크 학습이 어렵기에 이 문제를 해결하기 위하여 참조되지 않은 함수가 아니라 입력층을 학습하여 층을 만들어 “잔차 함수”(Residual function)라는 새로운 층을 만드는 통찰? 에서 시작되었다고 합니다.
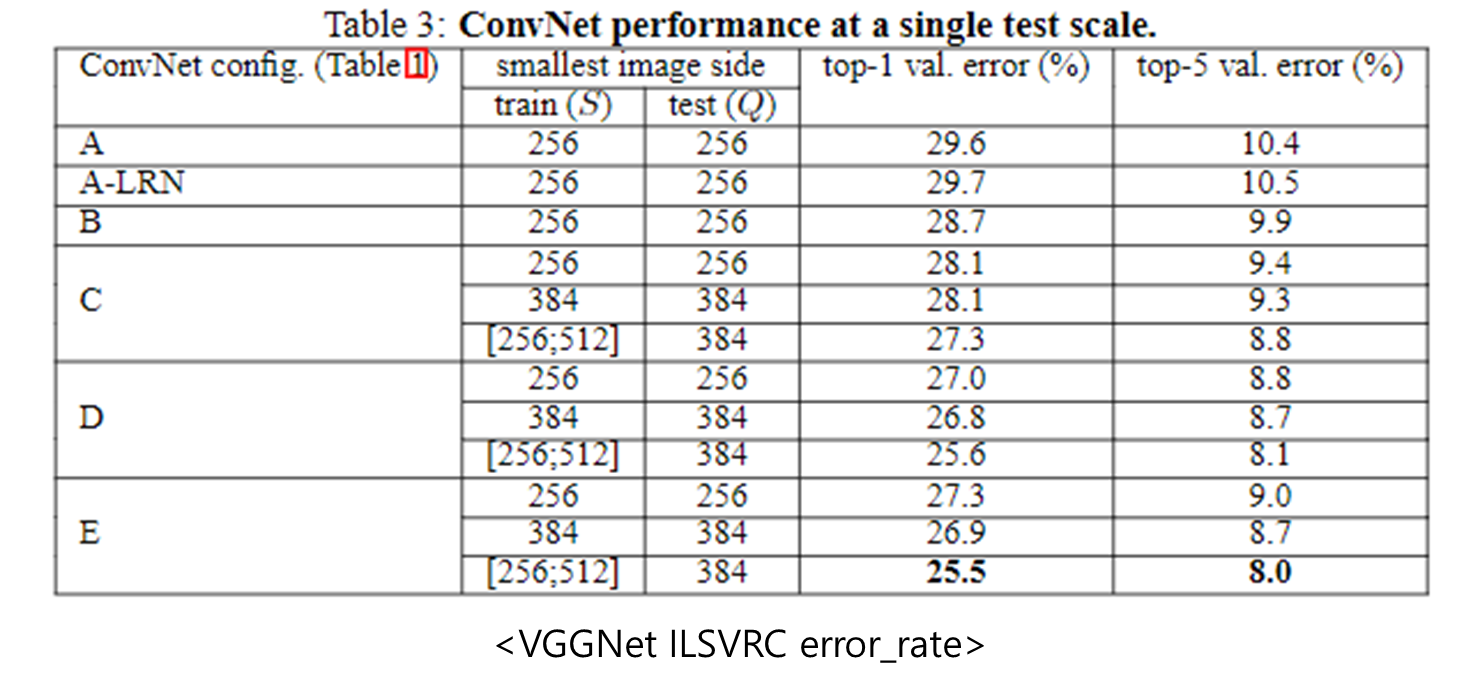
이후 2014년도에 top-5 에러율을 보여준 VGG19와 성능을 비교하는데 VGG19가 ILSVRC-2012 datase데이터셋에 top5 에러율 8.0을 달성한 데에 반해 ResNet은 top5 에러율 3.57을 달성했습니다. 눈에 띄는 점으로는 ResNet은 VGG19와 비교하여 이보다 8배 많은 152layer를 사용하였습니다.


Layer가 많아질수록(depth가 깊어질수록) 모델이) 좋아지는건 맞는데..., 아시다시피 가중치 소실, 폭주로 인하여 단순히 많은 층을 쌓는 건 좋은 생각이 아닙니다.
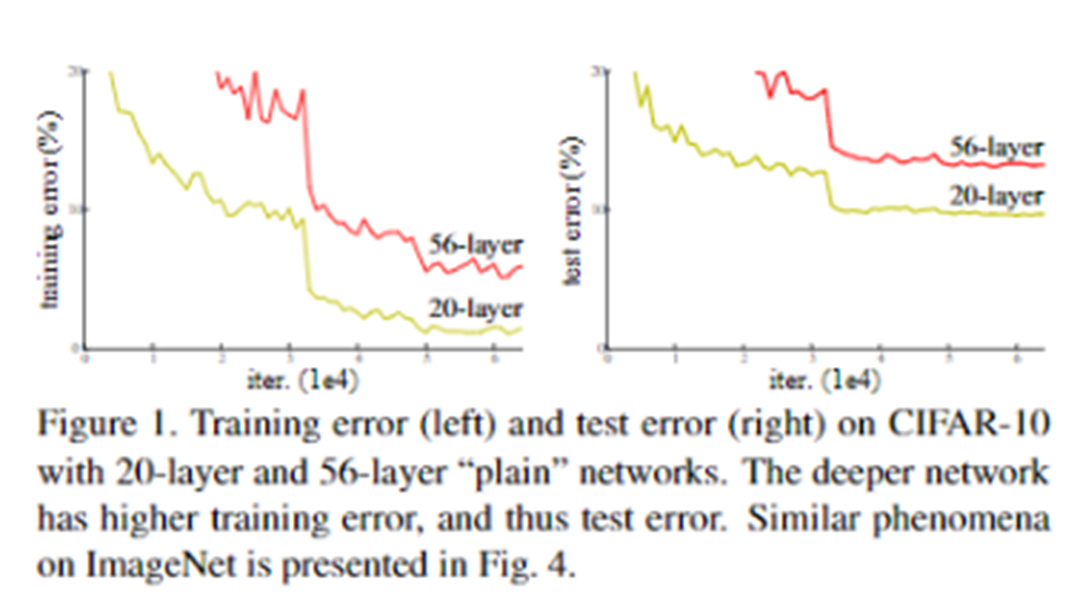
깊이가 깊으면 단순히 파라미터가 많아져 모델이 과대 적합된다고 생각할 수 있습니다. 하지만 저자는 모델의 성능을 최대로 만드는 layer이상을 쌓게될시 train, test set 모두에 대하여 성능이 낮아진다고 하였으며 이를 "degradation problem"이라 하였습니다.
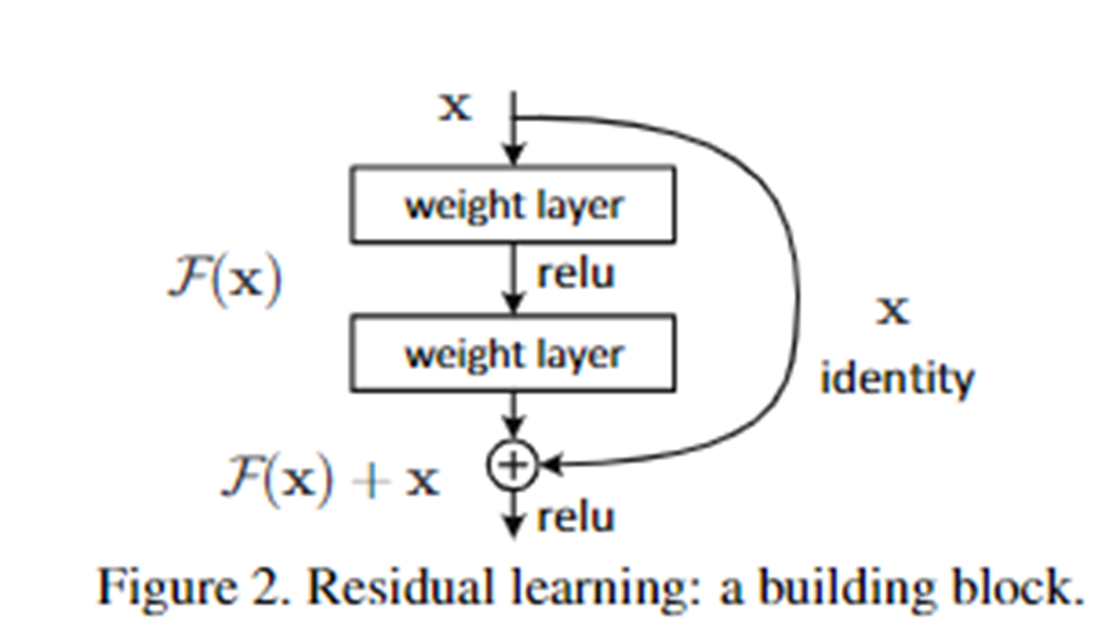
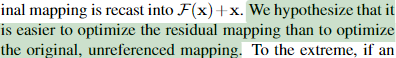
degradation problem을 해결하기 위하여 참조되지 않은 매핑을 최적화시키는 것이 어려워
잔차 구조를 고안하였다고 합니다.
층을 바로 연결하지 않고 몇 개의 층을 스킵하고 연결하여 F(x)라는 특정 layer에 국한된 함수를 0으로 만드는 학습이 가능해지며 모델이 이미 최적화되었을 때 층을 더 쌓아도 기울기가 소실/폭주되지 않도록 돕습니다.
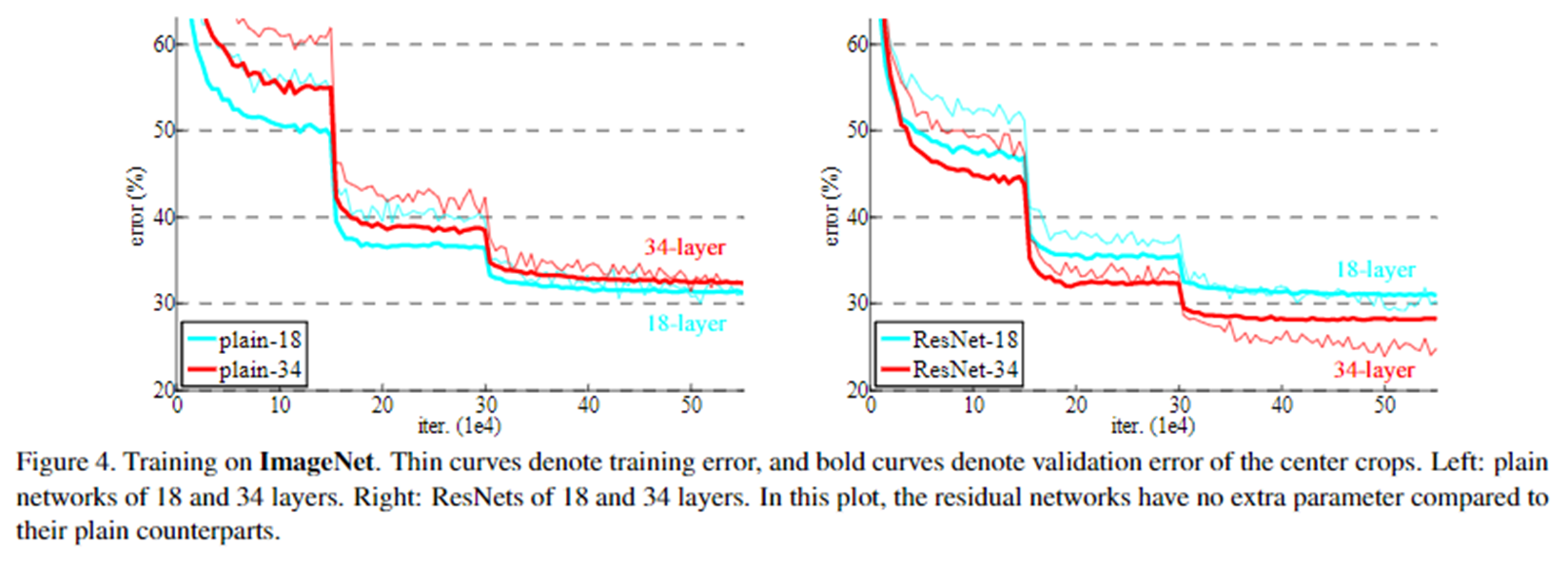
ResNet을 사용하는 경우 단순한 네트워크와 다르게 층이 깊어짐에따라 train과 test 셋에 대하여 error율이 모두 낮아지는 결과를 위의 그래프로 확인할 수 있습니다.

논문의 원리나 수식 같은 건 공부한 적이 있음에도 불구하고 실제로 구현하고 성능을 확인해본 건 처음이었는데
여태껏 봐왔던 다른 모델과 달리 구현이 정말 간단하였습니다. 한 가지 연산 추가만으로 놀라운 성능을 보여준 점에서 어째서 ResNet이 괜히 계속해서 회자되는 논문이 아니라는걸 깨달았습니다.
ResNet논문 링크: https://arxiv.org/abs/1512.03385
VGG논문 링크: https://arxiv.org/abs/1409.1556



