하반기 취준에 패배하고 대학원에 입학하고자 여러 분야의 논문을 가림 없이 읽고 있다. 그중 Few Shot Learning은 간간히 듣던 연구 주제라 개념을 잡기 위해 먼저 대표적인 Survey논문을 하나 읽고 리뷰해보려 한다.
Abstract & Introduction
Few-shot classification의 정의: 제한된 라벨의 데이터만을 사용하여 훈련시킨뒤 훈련 중에 보지 못한 라벨에 대해 분류하는 분류기를 만드는 것
저자는 논문에서 크게 세가지를 제안한다.
- 더 깊은 backbone이 도메인 차이가 크지 않은 데이터 간에 성능차이를 확연히 줄인다.
- few-shot데이터셋들에 대해 기존 SOTA보다 성능이 높은 baseline++을 제안
- FSL의 시나리오에 더 적합한 평가지표 소개
도입부에서는 기존 few-shot분류 알고리즘들은 크게 두 가지 이유로 알고리즘 간의 공정한 비교가 어려움을 서사한다.
- Few-shot algorithm별로 구현 디테일의 차이 존재
- 성능 평가는 같은 데이터셋 내에서 샘플링된 novel class를 분류하는하는것을 기준으로 함. 이런 방식은 base와 novel class간의 domain shift가 부족 즉, 평가시나리오가 현실적이지 않음
첫번째 원인에 대하여 모두 같은 backbone과 학습방식을 사용하는것으로 두번째 원인에 대해서는 학습과 성능 평가시 다른 데이터셋을 사용하는것으로 이를 보완한다.
Overview of Few-Shot Classfication Algorithms
이 단락은 크게 3가지 주제에 대해 설명하는 내용으로 이루어져있다.
1. Baseline model
2. Baseline++ model
3. Meta-learning algorithms

Baseline model
간단한 구조의 모델로 Few shot learning의 baseline model보다는 transfer learning이라 보면 이해가 더 편한 것 같다. Training stage에서 Feature extractor($f_{\Theta}$)와 Classifier를 학습하고 Fine-tuning단계에서 ($f_{\Theta}$)는 그대로 사용하고 기존 Classifier를 버리고 novel class의 개수에 맞는 새로운 Classfier를 학습하는 방식의 모델이다.
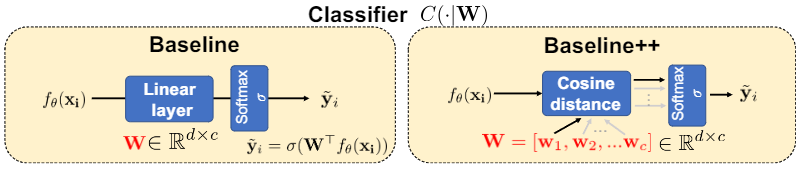
Baseline++ model
모델의 구조는 baseline모델과 동일하나 분류기의 학습방식에서 차이가 존재한다.
기존의 Classfier($W_b$)는 종종 사용하는 Linear모델로 행렬곱을 이용해 구현된다. 하지만 Baseline++는 입력 행렬의 전치행렬과 $W_b$의 코사인 유사도를 구해 구현한다. 이 방법이 d차원의 vector c개의 유사도와 같다고 한다. 연산결과를 [si,1 , si,2 , · · · , si,c]로 표기하며 유사도 점수로 명명했으며 이를 softmax를 통과해 결과를 예측했다. 이러한 방식이 기존 baseline보다 intra-class variation을 줄일 수 있음을 시사했다.
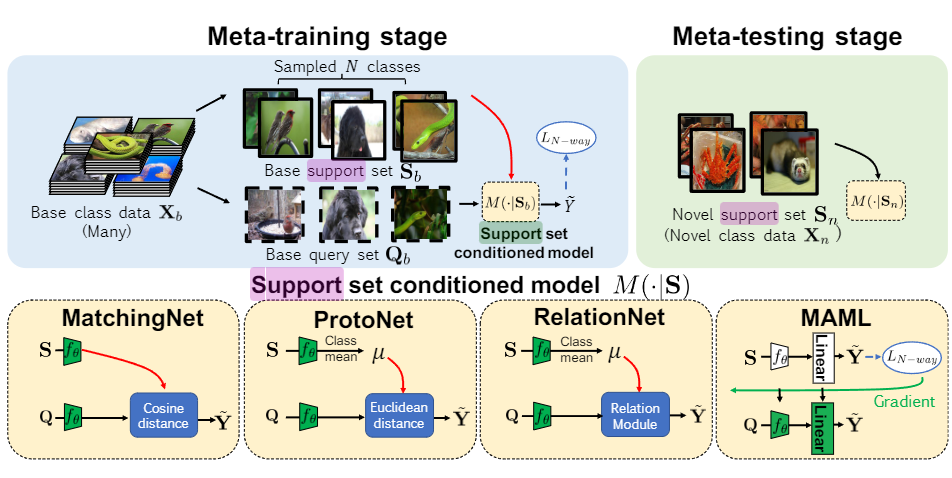
Meta-Learning Algorithms
Meta Learning은 Episode training이라고 불리는 학습법을 사용하여 모델을 학습하는데 N-way K-shot이라는 단어가 종종 나오는데 클래스 m개 중 n개의 라벨을 샘플링해 K개의 데이터만으로 학습하는 기법이다. episode training에 대한 자세한 설명은 이 블로그의 글을 통해 알 수 있다.
메타러닝 알고리즘들의 성능비교를 위해 4가지 방식의 메타러닝 Method를 사용하였다.
1. MatchingNet (Cosine distance)
2. ProtoNer (클래스 간 평균의 유클리드 거리)
3. RelationNet (Relation Module을 통해 자동으로 연산)
4.MAML (여러 support set의 loss를 통해 gradient update)
Experimental Results
평가는 Object Recognition, Fine-grained classification, cross-domain scenario 총 3개에 대해 진행된다.
1. Object Recognition(mini-ImageNet)
- ImageNet에서 추출한 100개의 클래스, 클래스당 600장의 이미지 포함
2. Fine-grained classification(CUB-200-2011)
- 200개의 클래스, 총 11788 이미지
3. cross-domain scenario (mini-ImageNet ->CUB)
- mini-ImageNet으로 pretrain, CUB으로 fine-tuning 및 validation
이후 Baseline계열과 Meta Learning계열 모두 구현 디테일(N-wat Kshot, BackBone model)등 구현 차이가 있는 부분을 모두 획일화시켰다.
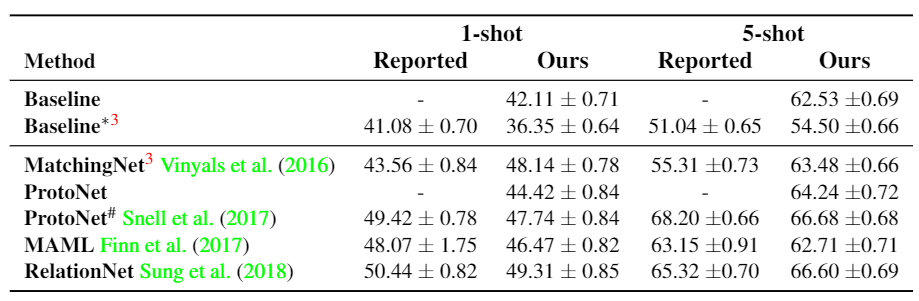
구현방법을 획일화시킨 뒤 기존과의 성능을 비교했을 때 큰 차이가 없음을 알 수 있다. 성능차이가 존재하는 부분은 Augmentation의 적용 혹은 Meta Learning에서 구현 디테일 차이에 의해 비롯됐다고 한다.

구현한 모델들로 실험을 진행한 결과이다. Baseline++가 CUB데이터셋에서는 성능이 제일 좋고 mni-ImageNet에서도 좋은 성능을 냈다.
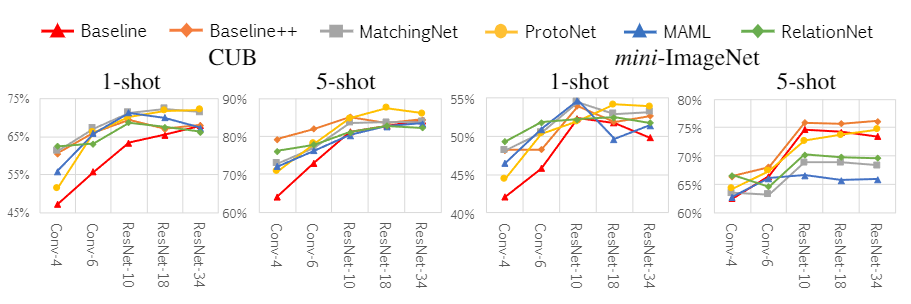
기존에는 Convolution layer 4개를 backbone으로 사용했는데 더 깊은 backbone에 대한 실험을 진행한 결과이다. CUB데이터셋에서는 깊은 backbone을 사용할 때 성능이 더 좋은 경향을 보이나 mini-ImageNet은 그렇지 않다. 저자는 이러한 결과가 deeper backbone에 의해 CUB 데이터셋의 intra-class variation이 줄어들었기 때문이라 주장한다.
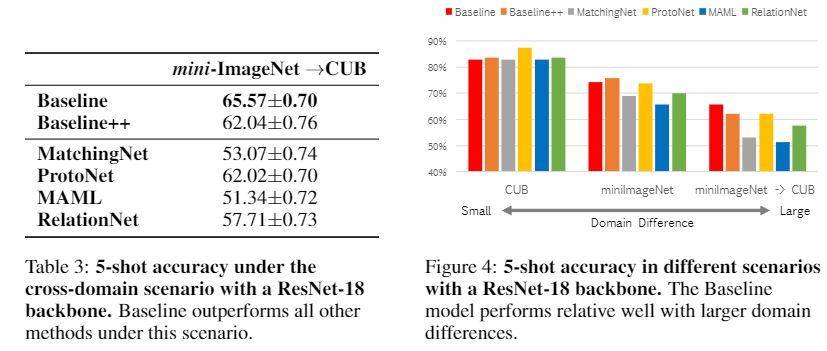
위에서 언급한 세 가지 실험 중 마지막인 domain adoptation에 대한 실험결과는 이와 같은데 genetal한 데이터셋(mini-ImageNet)에서 detail한 데이터셋(CUB)으로 파인튜닝하는게 현실의 시나리오와 유사함을 강조했다. (처음 볼 때는 사소했지만 이 검증 방법을 Contribution에 넣은 것을 보면 이 논문의 main part 중 하나인 것 같다.)
이 방식을 사용하면 기존의 Meta Learning방법론들은 꽤 낮은 성능을 보여주는데 이건 data 간의 domain이 너무 달라 모델의 적응이 불가능하기 때문이다. 반대로 baseline은 가장 좋은 성능을 보여주는데 이를 통해 data간의 domain차이가 클 때 추가적인 apaptation(transfer learning)이 중요함을 강조했다.

baseline과 같은 adaption을 Meta Learning 알고리즘에 적용시키니 성능이 좋음 역시 알 수 있는데 저자는 이를 통해 adaptation(여기서는 추가학습의 개념)의 중요성을 재강조한다.
Conclusions
도입부에 Contribution과 유사한 내용이며 추가적으로 FSL task의 새로운 검증방법을 통해 Baseline이 모든 다른 모델의 성능보다 월등했음을 시사한다.
Appendix
여러 변형 모델들과 구현 디테일에 관한 내용은 생략하고 Intra-class variation에 대한 내용은 논문 내에서 상당히 중요한 시사점 같아서 설명해 보겠다.
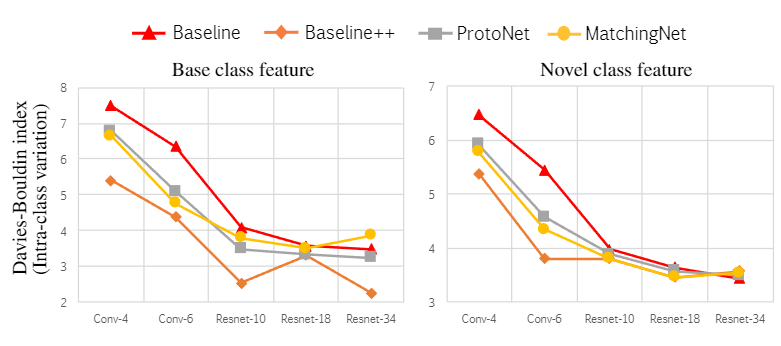
backbone의 차이에 따른 feature vector이후 값들의 Davies-Bouldin index(클래스 간 분리 정도?를 의미하는 듯 이게 낮을수록 군집이 더 잘 모여있다고 보면 됨)를 보여주는데 이게 위에서 언급한 deeper backbone -> low intra-class variation을 보여주는 자료이다. 추가적으로 Baseline++모델이 전반적인 Intra-class variation이 낮추는데 유리한 구조임을 재확인할 수 있다.
간단하게 FSL에 대해 알 수 있는 Survey논문이었으며 Contribution을 미리 정의한 부분이 좀 신기했지만 입문자 입장에서는 그 부분만 주요하게 읽고 모르는 부분은 중요 아이디어만 보는 느낌으로 빠르게 읽을 수 있어 편했다.
Embedding 할 때 더 가까운 embedding space에 존재하게 만드는 게 더 유리한 방법이라는 점을 feature extractor에 사용하기 위해 사용한 느낌인데 정확이 어떤 방식을 통해 Data point를 구했는지 이해도 안 되고 그로 인한 이점 역시 확 와닿지 않아서 이 부분에 대한 설명이 더 있었으면 읽기 편했을 것 같다.
논문링크: https://openreview.net/forum?id=HkxLXnAcFQ
SOTA링크: https://paperswithcode.com/paper/a-closer-look-at-few-shot-classification-1
(저자가 제안한 Metric을 확인할 수 있다)



