Transformer의 등장 이후 NLP 도메인에서는 이 구조를 활용한 논문이 쏟아져나왔고 GPT, BERT, ELMo등 이 구조를 성공적으로 활용한 다양한 논문 역시 등장하였다.
하지만 Vision분야에서도 이런 시도는 여럿 대부분 제한적으로 사용했으며 그 중에서 ViT는 Attention구조를 Vision분야에 성공적으로 적용시킨 최초의 시도 중 하나이며 지금도 CV를 다루는 사람들은 모를수가 없는 논문 중 하나이다.
NLP분야에서는 Transformer가 등장한 2017년 이후 2018~2019년도에는 이를 변형한 모델들이 등장해 좋은 성적을 내 눈길을 끌었다. Transformer와 Attention구조가 그렇게 뛰어나다면 어째서 Vision분야에서는 이러한 모델이 등장하지 않는걸까?
저자는 논문 전체에 걸쳐 이 이유와 이를 극복하고 Attention구조를 활용하여 Classification문제를 다루기 위해 택한 방법을 서술한다.
Abstract, Introduction
NLP분야에서는 Transformer구조는 이미 새로운 기준이 되었지만 Computer Vision분야에서는 아직 CNN의 형태와 결합하여 사용되고 있는 점을 꼬집었으며, CNN에 의존하지 않고 Transformer만으로 Image Classification문제를 다루기 위해 다양한 실험을 진행하였다.
이미지를 Attention구조에 적용시키기위해 사용한 방법은 이미지를 패치로 나누고 Linear layer를 통과시킨 다음 패치들을 Transformer의 Input으로 사용하는 것이다. 즉 이미지의 패치들이 Transformer의 하나의 단어로서 취급된다.
ViT는 ImageNet을 Pretrain했을때는 ResNet보다 성능은 조금 낮다. 하지만 ImageNet-21k, JFT-300M과 같은 대용량 데이터셋을 사용하면 기존의 벤치마크보다 우수한 성능을 보여준다. 저자는 이러한 결과가 Transformer의 부족한 Inductive bias는 현재 통용되는 CNN보다 낮은것을 이유로 들었다.
이때 CNN은 translation equivariance와 locality와 같은 특징으로 인해 Inductive bias가 크다고 말하는데 이는 우리가 CNN을 배울때 자주 언급되는 "CNN은 같은 필터의 공유로 이미지 내의 위치 이동 혹은 변환에 강하다"는 점이 적용되고 있기 때문이다.
Related Work
Transformer와 BERT, GPT등 NLP에 성공적으로 활용한 예시들과 CNN과 Attention구조를 결합한 기존의 시도를 나열했다. 기존의 Vision분야에서 패치의 개념을 적용시킨 예시가 ViT와 유사하다고 언급했으나 개인적으로 BERT의 class token개념을 알고 있는게 모델의 구조 이해에 더 도움이 됐었다.
Method
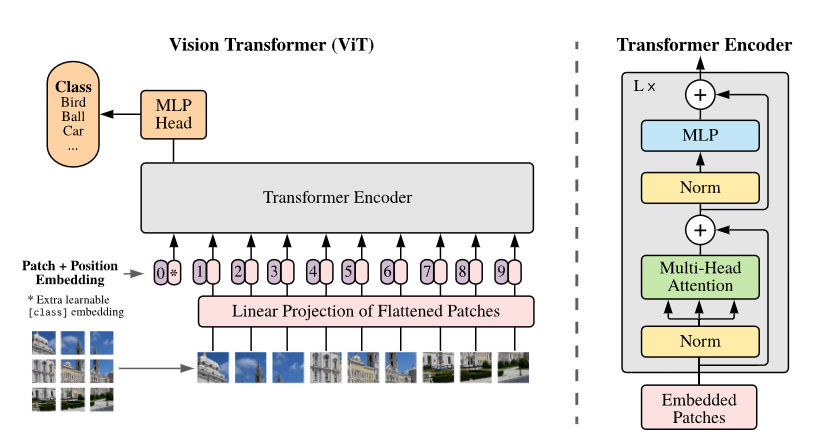
전반적인 순서는 아래와 같다.
1. Input Image(H * W * C)를 패치로 자름 -> Patch(N * P^2 * C) 여기서 N은 나눠진 패치의 개수로 N = HW/P^2으로 구할 수 있다.
2. 각 패치를 flatten시킨 후 Linear layer를 거쳐 D차원 patch embedding 변환한다.(D는 Transformer의 d_model과 유사하게 Encoder를 여럿 거쳐도 이 size를 유지한다)
3.BERT의 [class] 토큰의 개념을 활용 patch embedding의 제일 앞에 추가한다.
4. 이미지의 공간정보를 유지하기 위해 patch embedding에 1차원 posotion embedding을 추가한다.(positional encoding이 아니라 position embedding을 사용함)

인코더는 Transformer과 동일하게 MSA, MLP layer를 거치는데 입력 이전에는 Layer normalization을 입력 후에는 Residual connection을 사용한다. 유일하게 다른점이라면 activation function으로 Transformer에서 사용한 ReLU가 아닌 더 트렌디한 GELU를 사용했다는 점이다.
Fine Tuning
ViT는 finetuning시 pre-trained predicition head를 제거하고 [D*K]의 feedforward layer를 사용한다고 한다. (method에는 기재되어있지 않지만 아마 출력시퀀스의 첫 출력값 [1*D]를 N개의 클래스로 predict해주는 모델을 사용하고 이를 fine-tuning하는것 같다)
finetune할때 pretrain보다 높은 이미지를 사용하는 경우 보통 좋은 성능을 보여주는데 이때 기존의 pretrain된 position embedding은 finetune시킬 이미지와 동일한 사이즈로 interpolation시킨다.
저자는 위의 resolution adjustment(to position embedding)과 patch extraction만이 ViT에서 모델에 inductive bias를 주입하는 과정이라 말했다.
Experiments
실험은 총 3개의 모델(ResNet, ViT, hybrid ViT)에서의 성능을 비교하였다.(hybrid는 CNN의 feature map을 patch embedding으로 사용한다) 다양한 크기의 데이터셋으로 사전훈련 후 벤치마크 테스트를 진행했다.
Dataset
pretrain을 위해 총 3개의 데이터셋을 사용했다.
- Imagenet(1k classes, 1.3M images)
- Imagenet-21k(21k classes, 14M images)
- JFT(18k classes, 303M high resolution images)
fine-tuning후 성능 비교를 위해 사용한 데이터셋은 아래와 같다.
- Imagenet(valset)
- Imagenet(ReaL labels)
- CIFAR-10/100
- Oxford-IIIT Pets
- Oxford Flowers-102
- 19-task VTAB classification suite
ViT는 성능평가에 총 3개의 버전을 사용했다.
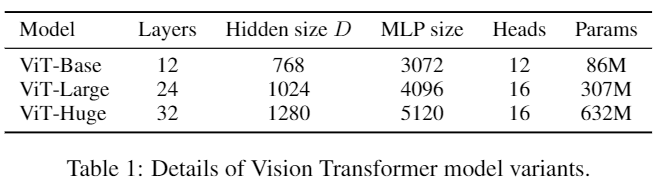
Comparision to State of the art
성능 비교를 위해 BiT와 EfficientNet_Noisy sturent를 사용했다 EfficientNet은 ImageNet에서 BiT-L을 다른 데이터셋에서 SOTA를 달성한 이력이 있다.
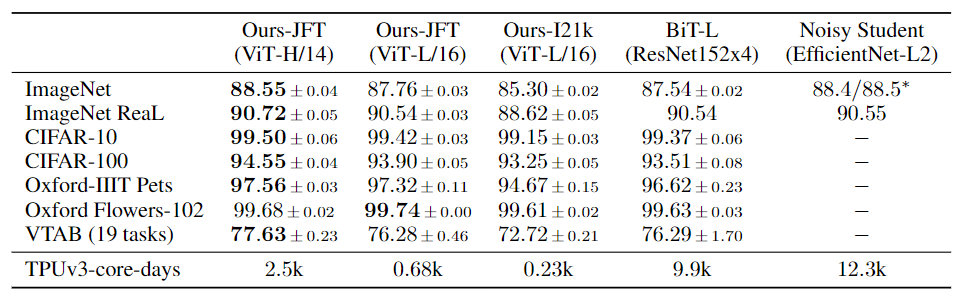
성능을 비교한 결과는 위와 같은데 대부분의 데이터셋에서 기존 모델보다 좋은 성능을 보여줄뿐만 아니라 같은 자원을 사용해 훈련했음에도 훈련이 제일 빠른 모습을 보여준다.
Pre-training Data Requirements
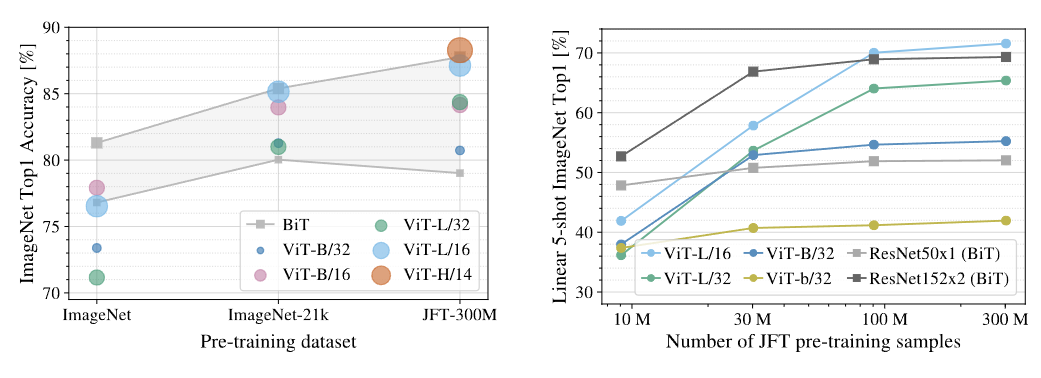
위 표는 사전학습에 사용하는 데이터셋을 변경해가며 성능을 비교한 결과이다. 회색으로 크게 칠해진 부분은 BiT와 그 변형들의 성능이 차지하는 영역을 나타낸다. 이를 통해 ViT는 더 큰 데이터셋을 통해 사전학습할때 좋은 성능을 보여줌을 알 수 있다.
Conclusions
저자는 ViT가 초기의 패치 추출단계를 제외하고 추가적인 image-specifit inductive bias를 추가하지 않고 self-attention을 CV에서 사용한 모델이라는 점을 제시했다. ViT는 상대적으로 큰 데이터셋에서 놀라운 성능을 보여주었으며 훈련시 자원 효율성의 뛰어남 역시 부여주었다.
예전에 친구가 CV도메인에서 Inductive bias의 control이 정말 중요한 개념이라고 들은적이 있는데 이번 논문을 읽으며 갑자기 그 생각이 났다. 논문의 저자 역시 Transformer의 Inductive bias부족은 CV의 도메인적 특성과 어울리지 않는다는 기존의 아이디어를 인지하고 있었던것 같고 ViT를 제시해 이를 어느정도 극복한 결과를 보여주었다.
mmdetection이나 segmentation 라이브러리를 사용할때는 눈에띄는 차이를 느끼지 못했는데 실험결과를 보니 학습시킬 데이터셋이 클수록 성능이 월등하니 아마도 기존의 data와 fine-tuning했던 data 분포 차이가 큰데 그 차이를 뛰어넘을 정도의 데이터를 구하지 못해 그랬던거아닐까 생각한다.
논문을 읽고 궁금해서 오랜만에 SOTA에 들어가서 확인해보니 CV의 많은 논문이 ViT의 변형인걸 보니 ViT가 CV계에 미친 영향이 크다는걸 다시 한번 실감할 수 있었다. 아마 새로운 아키텍쳐가 고안되지 않는 이상 데이터는 점점 많아지니 간단한 task에서는 Transformer구조가 결국 NLP도메인 처럼 새로운 기준이 될 날이 올 가능성도 있다고 생각한다.
'Paper review' 카테고리의 다른 글
| Generative Adversarial Nets(GAN, 2014) 리뷰 (1) | 2023.12.20 |
|---|---|
| A Closer Look at Few-shot Classification(2019) 리뷰 (0) | 2023.12.15 |
| [Paper review] Convolutional Networks for BiomedicalImage Segmentation(U-Net, 2015) (0) | 2023.06.19 |
| [Paper review] Rich feature hierarchies for accurate object detection and semantic segmentation(RCNN, 2014) (0) | 2023.05.31 |
| [Paper implementation] ResNet구현 (1) | 2023.04.12 |



