0.GPU 지정
아래처럼 쓰는 이유는 python에서 device설정할때 인자로 넘기는 것보다 이게 더 확실하고 편해서
그리고 device_map: "auto" 와 조합해서 모두 커버 가능해서
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0" # "0"을 원하는 GPU 인덱스로 변경1.AutoClass 불러오기
from transformers import AutoTokenizer, AutoModelForSequenceClassification, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-cased")
model = AutoModelForSequenceClassification.from_pretrained("google-bert/bert-base-cased", num_labels=2)Some weights of BertForSequenceClassification were not initialized from the model checkpoint at google-bert/bert-base-cased and are newly initialized: ['classifier.bias', 'classifier.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.가장 마지막줄에 Some weights~는 BERT가 Sequence classifiacion에 적합한 layer가 없다는 뜻
그렇다고 안되는건 아니고 embedding 느낌으로 사용하고 Sequence classifiaction에 적합한 층이 추가됨
temp_model = AutoModelForMaskedLM.from_pretrained("google-bert/bert-base-cased")Some weights of the model checkpoint at google-bert/bert-base-cased were not used when initializing BertForMaskedLM: ['bert.pooler.dense.bias', 'bert.pooler.dense.weight', 'cls.seq_relationship.bias', 'cls.seq_relationship.weight']MLM은 다른 경고가 뜬다. 이건 사용하지 않는 layer가 있다는 뜻(아마 NSP나 다른 task를 위한 무언가)
2. Dataset 정의
from datasets import load_dataset
dataset = load_dataset("SaylorTwift/bbh", "navigate")
# dataset["train"][100]datasetDatasetDict({
test: Dataset({
features: ['input', 'target'],
num_rows: 250
})
})보통 DatasetDict 형태로 데이터셋을 만든다
dataset = dataset.rename_column("input", "text")
dataset = dataset.rename_column("target", "label")tokenizer가 받는 특정 key가 있어서 그에 맞게 rename
def tokenize_function(examples):
examples["label"] = 1 if examples["label"] == "Yes" else 0 #batched=True 안먹힘
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function)print(type(tokenized_datasets))
print(type(tokenized_datasets["test"]))<class 'datasets.dataset_dict.DatasetDict'>
<class 'datasets.arrow_dataset.Dataset'>tokenized_datasets["test"].select([0])Dataset({
features: ['text', 'label', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 1
})small_train_dataset = tokenized_datasets["test"].select(range(0, 150))
small_eval_dataset = tokenized_datasets["test"].select(range(150, len(tokenized_datasets["test"])))small_train_datasetDataset({
features: ['text', 'label', 'input_ids', 'token_type_ids', 'attention_mask'],
num_rows: 150
})2. TrainingArguments 세팅
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(output_dir="test_trainer", eval_strategy="epoch", learning_rate=1e-5,num_train_epochs=10
)import numpy as np
import evaluate
metric = evaluate.load("accuracy")def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)model = AutoModelForSequenceClassification.from_pretrained("google-bert/bert-base-cased", num_labels=2)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
)Some weights of BertForSequenceClassification were not initialized from the model checkpoint at google-bert/bert-base-cased and are newly initialized: ['classifier.bias', 'classifier.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.trainer.train()<div>
<progress value='190' max='190' style='width:300px; height:20px; vertical-align: middle;'></progress>
[190/190 00:41, Epoch 10/10]
</div>
<table border="1" class="dataframe">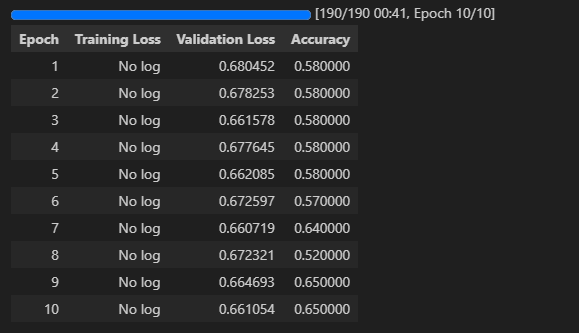
TrainOutput(global_step=190, training_loss=0.6742290296052632, metrics={'train_runtime': 43.1136, 'train_samples_per_second': 34.792, 'train_steps_per_second': 4.407, 'total_flos': 394666583040000.0, 'train_loss': 0.6742290296052632, 'epoch': 10.0})학습이 제대로 되는지를 모르겠다. GPT선생님 추천 dataset 사용
감성분류 한번 조져보자
from datasets import load_dataset
dataset = load_dataset("imdb")
train_dataset = dataset['train']
test_dataset = dataset['test']
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
train_dataset = train_dataset.map(tokenize_function, batched=True)
test_dataset = test_dataset.map(tokenize_function, batched=True)from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(output_dir="test_trainer", eval_strategy="epoch",learning_rate=1e-5
)small_train_dataset = train_dataset.shuffle(seed=42).select(range(1000))
small_eval_dataset = test_dataset.shuffle(seed=42).select(range(1000))model = AutoModelForSequenceClassification.from_pretrained("google-bert/bert-base-cased", num_labels=2)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
)Some weights of BertForSequenceClassification were not initialized from the model checkpoint at google-bert/bert-base-cased and are newly initialized: ['classifier.bias', 'classifier.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.trainer.train()<div>
<progress value='375' max='375' style='width:300px; height:20px; vertical-align: middle;'></progress>
[375/375 01:25, Epoch 3/3]
</div>
<table border="1" class="dataframe">
TrainOutput(global_step=375, training_loss=0.37965966796875, metrics={'train_runtime': 86.0023, 'train_samples_per_second': 34.883, 'train_steps_per_second': 4.36, 'total_flos': 789333166080000.0, 'train_loss': 0.37965966796875, 'epoch': 3.0})
