2주동안 CV 기본지식으로 Image Classification부터 ViT까지 배웠는데 강의가 극한으로 압축되어 있어
나도 그렇고 다른 사람들 역시 많은 부분을 이해하지 못하고 넘겼다.
모든 부분은 디테일하게 짚고 넘어가는게 최선이지만 강의, 과제, 팀 활동이 계속해서 늘어나므로
디테일한 부분이나 구현을 제외하고 개념만 정리하고 느낌만 알아보는 식으로 가겠다.
이 후 여러 task 역시 이런식으로 정리할텐데 프로젝트를 진행하기 전 먼저 시야를 넓게 가져보기에는 좋은 방법인것 같다.
Semantic Segmentation
아마 이글을 읽는 사람 중 이 용어가 의미하는 바는 없을거라 생각된다.
간단히 말하자면 "이미지의 픽셀별 분류"라고 생각하면 될것 같다.(엄밀히 말하자면 upsamplig을 거치므로 픽셀보다는 조금 rough한)

Fully Convolution Networks
FCN은 Segmentation task에서 최초의 end-to-end 모델이며 임의의 input size를 받을 수 있다.
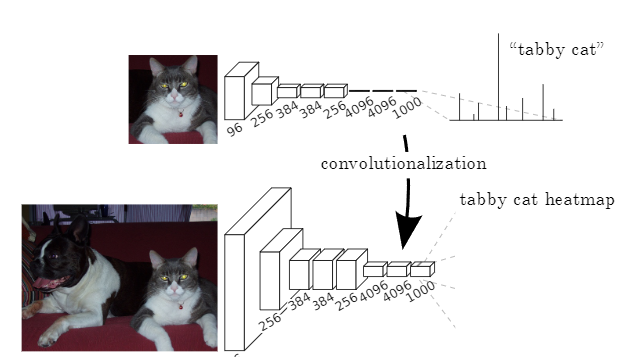
FCN의 upsampling 이전의 단계를 위에서 볼 수 있는데
저자는 기존의 [4096, h, w] -> [1000]의 형태로 이루어지는 linear 연산을
[4096, h, w] -> [1000, h, w] 형태의 1x1 convolution 연산으로 변경하였다. 이로 인해 기존의 1000클래스 분류기가 출력층 이전의 output[4096, h, w]의 h, w를 훑을 수 있게 되었다.
이러한 연산의 한계점 역시 존재하는데
1. 연산 후 나오는 [n_classes, h, w]는 분류기를 통해 거친 Max plooling으로 인해 상당히 해상도가 낮은 조악한 이미지이다.
2. 위와 같은 동작 방식이면 낮은 h, w를 가진 이미지는 연산 후 더 낮은 h, w를 갖게 되는데 이를 방지하기 위해 resize 혹은 작은 사이즈의 모델이 필요할 것 같다. 근데 여기서 resize를 쓰면 기존의 end-to-end의 특성이 맞는건가에 대한 의문이 있다.(task를 아직 다 파악하지 못한 개인적 견해이다)
Upsampling
모델 예측 후 조악한 이미지에서 기존의 이미지 사이즈로 돌아기기 위해 사용하는게 upsampling이다.
그 중 대표적인게 바로 Transposed Convolution이다.
Transposed Convolutional Layer은 무엇인가?
Transpoed convolution과 deconvolution은 다름 transposed Convolutional Layer는 Deconvolutional layer라고 잘못알려져 있습니다. Deconvonutional layer는 일반적인 convolutiona
velog.io
자세한 설명은 위 블로그에 나와 있는데
간단히 말하자면 Convolution의 출력과 입력의 순서를 바꾼 일종의 역연산이라 보면 될것 같다.

FCN은 추가적으로 업샘플링 과정 중에 이전 층의 가중치를 연결시키는 Skip-connection을 사용하였다.
필터를 거치며 이미지 사이즈가 점점 작아지다 이후 upsampling을 거치는데 h, w가 같아질때 이를 더해줌으로 복원시 detail을 조금 더해줄 수 있다고 한다.
U-Net

구조만 보면 FCN과 큰 차이는 없어보였다.
가장 큰 차이점은 skip-connection시 FCN은 position-wise add 연산을 사용했지만 U-Net은 concat을 사용하였다.
모델성능을 높이기 위한 다양한 기법이 적용되었다는데 의료 domain에 치중된 얘기 같아 더 다루지는 않겠다.
밑줄 아래칸은 언제나 내 뇌피셜이니 그냥 이 사람은 이렇게 생각하나보네~ 정도로 봐주면 될것 같다.
수업을 듣기전까지만해도 Segmentation이 Detection보다 당연히 더 어려울 줄 알았지만
단순 개발 난이도로 보면 구현이 어려운 편은 아닌것 같아 놀랐다.
예측 정확도 역시 높아보여서 솔직히 detection보다 segmentation모델을 고도화 시키는게 더 유리해 보이는데 왜 detection알고리즘만 우후죽순 생겨나고 있는지 궁금하기도 하다.
조금 깊게 생각해보니 Segmentation은 영역을 쪼개는 느낌이므로 작은 물체를 놓치기 쉽고 출력으로 이미지를 뱉기에 직접 사용하기 위해서 전처리가 필요할것 같다.
이렇게보니 segmentation이 어째서 의료 데이터 문제에서 자주 보이는지 알 것 같다. 아마 큰 객체를 detail하게 영역을 뽑고 그 출력을 의사나 환자가 직접 사용하기 때문에 이미지를 출력하는게 이상적이다.
하지만 detection 알고리즘은 여러 객체를 rough?(사각형이니...)하게 예측하고 출력이 bbox + class형태이다. segmentation보다 출력량은 적으나 객체 정보만을 포함하고 있으므로 실시간성을 요구하는 task(자율주행과 같은)에 유리할것이라 생각된다.
'Boostcamp' 카테고리의 다른 글
| [부스트캠프] object detection overview (1) | 2023.05.03 |
|---|---|
| [부스트캠프] Transformer 정리 (0) | 2023.04.25 |
| [부스트캠프] ResNet 정리 (0) | 2023.04.06 |
| [부스트캠프]Pandas 정리 (0) | 2023.03.18 |
| [부스트캠프]Numpy정리 (1) | 2023.03.18 |



